Introduction
The Hadoop file system is designed as a highly fault-tolerant file system that can be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large datasets.
HDFS is designed for batch processing rather than interactive use by users. HDFS provides write-once-read-many access models. In this model, once a file is created, written and closed, it can not be changed except for appending and removing. HDFS does not support hard links or soft links.
HDFS Architecture
HDFS has a master/slave architecture. A cluster consists of a NameNode along with one or more DataNodes, usually one per node in the cluster. A file is split in one or more blocks (128 MB by default) and these blocks are stored in a set of DataNodes.
Name Node
The NameNode manages the file system by storing the metadata and is the centerpiece of HDFS. NameNodes keep track of metadata such as number of data blocks, file names and their path, block IDs, block locations, number of replicas and slave related configuration. NameNode keeps the directory tree of all files in the file system, and tracks where across the cluster the file data is kept. It does not store the actual data of these files itself. There is only one active NameNode that serves as the master in the cluster. NameNode keeps track of the metadata in the memory, so usually NameNodes have lots of RAM. NameNode manages the slave nodes and assign tasks to them.
Metadata in HDFS is maintained by two files (both local file in NameNode file system):
Edit Log: Record every change that occurs to file system metadata
FS Image: The entire file system namespace, including the mapping of blocks to files and file system properties, is stored in FS Image.
The above two files are the central data structure of HDFS. Any corruption of these files can cause the HDFS instance to be non-functional. For this reason, the NameNode can be configured to support maintaining multiple copies of the FsImage and EditLog. Any update to either of these files causes an asynchronous update to its copy.
Any change to the file system namespace or its properties is recorded by the NameNode. For example, if a file deleted in HDFS, the NameNode immediately records this in the edit log.
NameNode periodically receives a heartbeat and a block report from all the DataNodes in the cluster. NameNode also takes care of the replication factor of all the blocks. NameNode is a single point of failure in the Hadoop cluster. The NameNode makes all decisions regarding the replication of blocks.
Data Node
Data Node is the slave daemon in the HDFS and stores the actual data. DataNode handles the read, writes and data processing and it creates, deletes and replicates the data blocks uppon NameNode requests.
DataNodes store HDFS files in their local file system and the have no knowledge about HDFS files. Meaning that from their point of view all those HDFS files are regular files in their file systems. DataNode does not create all the files in the same directory because the local file system might not efficiently support a huge number of files in a single directory.
DataNodes usually have lots of disk space since they are responsible for the storage and they can be deployed on commodity hardware.
DataNodes sends periodic heartbeat as well as information about the files and blocks stored in that node to the NameNode. When a DataNode starts up it announces itself to the NameNode along with the list of blocks it is responsible for. In the scenario when NameNode does not receive a heartbeat from a DataNode for 10 minutes, the NameNode considers that particular DataNode as dead and starts the process of Block replication on some other Data Node.
Data Replication
HDFS stores each file as a sequence of blocks. These blocks are replicated for fault tolerance. The block size and replication factor are configurable per file. All blocks of a file except the last one are the same size. The replication factor can be specified at the file creation time and can be changed later.
When a new file is created, the NameNode will retrieve a list of DataNodes using a replication target choosing algorithm. This list contains the DataNodes that will host a replica of that block. The clients then writes to the first DataNode and in turns that DataNode starts to receive each portion of data block and writes those into its local repository and then start transferring those portion to the second DataNode in the list. The second DataNode then start receiving each portion and write them in its local repository and send them to the next DataNode. Thus, a DataNode can be receiving data from the previous one in the pipeline and at the same time forwarding data to the next one in the pipeline. The ACK then starts to come from the last DataNode to the previous one all the way to the first DataNode and finally to the NameNode and that transaction considered fully committed.
The DataNodes sends a periodic heartbeat to the NameNode and if the NameNode does not receive the heartbeat from the DataNode (10 mins by default) it will mark that DataNode as dead and won’t forward any IO operation to the dead DataNode. In this case, the number of replication may fall under the threshold and NameNode might initiate the replication of the data on the dead DataNode to another DataNode.
The re-replication might happens for the DataNode failure or network failure or even the corruption of the blocks in any of the DataNodes. The replication factor of a file may increase at any time which can cause the re-replication as well.
Rack Awareness
Rack awareness provides data availability in the events of a network switch failure or network partition within the cluster. Master daemon or NameNode obtain the rack ID of the cluster workers by invoking either an external script or java class as specified by configuration files. The format is “/rackID/hostID”.
Rack Awareness increases the cost of writes because each writes each block needs to be distributed among racks to achieve data availability. If the replication factor is 3, then the blocks would reside in two different racks such that there would be one copy of the block in one node in a rack and two more copies in two more nodes in another rack.
If replication factor is more than 3, then the location of the 4th and the following replicas are determined randomly while keeping the number of replicas per rack below the upper limit which is (replica – 1 ) / racks + 2)
The maximum number of replicas created is the total number of DataNodes at the time of creation.
Checkpoint
The purpose of checkpoint is to make sure HDFS has a consistent view of the file system metadata by taking a snapshot of the file system metadata and saving it to FsImage. When the NameNode starts up, it reads the FsImage and EditLog from disk, applies all the transactions from the EditLog to the in-memory representation of the FsImage, and flushes out this new version into a new FsImage on disk. It can then remove the old EditLog since its transactions have been applied to the persistent FsImage. This process is called checkpoint.
dfs.namenode.checkpoint.period: Configure the checkpoint triggering in sec
dfs.namenode.checkpoint.txns: Configure the checkpoint triggering by the number of transactions.
Communication Protocol
All the HDFS communication protocols are layered on top of TCP/IP. There are client protocol and DataNode protocol.
The client initiates the communication with the NameNode using the client protocol and the DataNode initiates the communication to the NameNode using the DataNode Protocol. The NameNode never initiates any RPC and instead just response to the requests from clients and DataNodes.
NameNode High Availability (HA)
NameNodes are the single point of failure in the Hadoop cluster. Due to this fact, NameNodes are usually deployed on reliable hardware. However, the best practice for providing high availability in Hadoop cluster is to have a second NameNode as hot standby.
HDFS NameNode HA architecture provides the option of running two redundant NameNodes in the same cluster in an active/passive configuration with a hot standby.
Active NameNode: Handles all client operations in the cluster.
Passive NameNode: This is a hot standby name node, which has similar data as active NameNode. It acts as a slave and maintains enough state to provide a fast failover, if necessary.
In order to make the standby NameNode hot and ready to take over the full responsibility of the active NameNode, it should be in sync with the active name node constantly.
There should be only one active NameNode at a time in the cluster. Otherwise, two NameNodes will lead to the corruption of the data. We call this scenario as a “Split-Brain Scenario”, where a cluster gets divided into the smaller cluster. Each one believes that it is the only active cluster. “Fencing” avoids such scenarios. Fencing is a process of ensuring that only one NameNode remains active at a particular time.
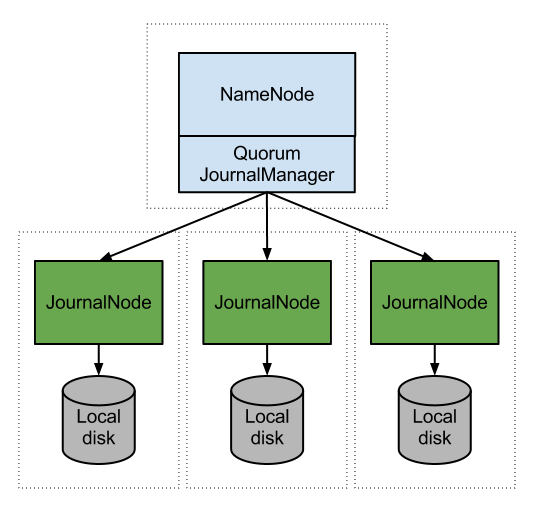
Quorum Journal Nodes is the recommended way of implementation of HA in a Hadoop cluster.
JournalNode (JN): In order for the Standby node to keep its state synchronized with the Active node, both nodes communicate with a group of separate daemons called “JournalNodes” (JNs). The minimum number of JNs should be at least 3 nodes and they can be colocated by any other Hadoop daemons, for example, NameNodes, the JobTracker, or the YARN ResourceManager and they don’t need a dedicated host.
When any namespace modification is performed by the Active node, it durably logs a record of the modification to a majority of these JNs. The Standby node is capable of reading the edits from the JNs and is constantly watching them for any change. In other words, the edit log has to be stored by the JNs as opposed to a normal scenario that a single NameNode stores the edit log locally. In the event of a failover, the Standby will ensure that it has read all of the edits from the JounalNodes before promoting itself to the Active state. This ensures that the namespace state is fully synchronized before a failover occurs.
In order to provide a fast failover, it is necessary that the standby node maintain the up-to-date information of the blocks in the cluster. In order to achieve this, all DataNodes need to be configured with the location of both active and standby NameNodes and they have to send the block report and heartbeats to both.
In order to prevent the split-brain scenario, the JNs allow only one NameNode to be a writer at the time.