Introduction
In this post, I am going to go over a simple project running on Amazon EMR. I am using a dataset “Baby Names from Social Security Card Applications In The US” which holds the data for 109 Years (1910-2018). I transformed the data to make it compatible with this project and made it available in Github. I converted the CSV files to Parquet format and used both of them to compare the performance.
In this project, I use S3 to store both CSV and Parquet files and then expose them as Hive tables and finally use Hive and Presto to issue some SQL queries to do simple analytics on the data stored in S3.
Before we start, I would like to consider why should we use Amazon EMR and not our own Hadoop cluster.
There are multiple reasons for choosing EMR over an on-premise Hadoop cluster however to me, the most important ones are:
- Cost Efficiency
- Decoupling of Storage and Compute
You can launch a Hadoop cluster in Amazon with few clicks or by running a script, Terraform or similar, do your work and analytics, and destroy the entire cluster afterward. Doing this in your own environment may not be as fast and cost-effective as using EMR. Furthermore, usually speaking when Hadoop is deployed on-premises, storage and compute are coupled together. Imagine if you have multiple clusters (Cluster A & B) and you want to access the HDFS data that you have in cluster A from Cluster B. This can be a problematic and troublesome task. However, if the data is sitting in a centralized place (in this case S3) you can easily access your data regardless of which cluster you are using. This also makes your data durable and protected against the termination of your clusters.
using S3 as the underlying storage allows for a better way to scale your compute without scaling your storage or vise versa. This also means not dealing with the HDDs and SSDs yourself. Amazon S3 is also extremely reliable and durable data storage.
Another advantage of using EMR is the options that we have as a customer for the choice of our virtual machines which can be different based on our workloads. There are storage-optimized, memory-optimized, and compute-optimized family instances as our options available on EMR. Using Amazon EMR makes it easy to interact with your data in S3. This might not work out of the box for all the components in an on-premises Hadoop environment.
Launching EMR
I use pretty much all the default settings and create a new cluster using the AWS console. I choose only Hadoop 2.85, Hive 2.3.6 and Presto 0.227.
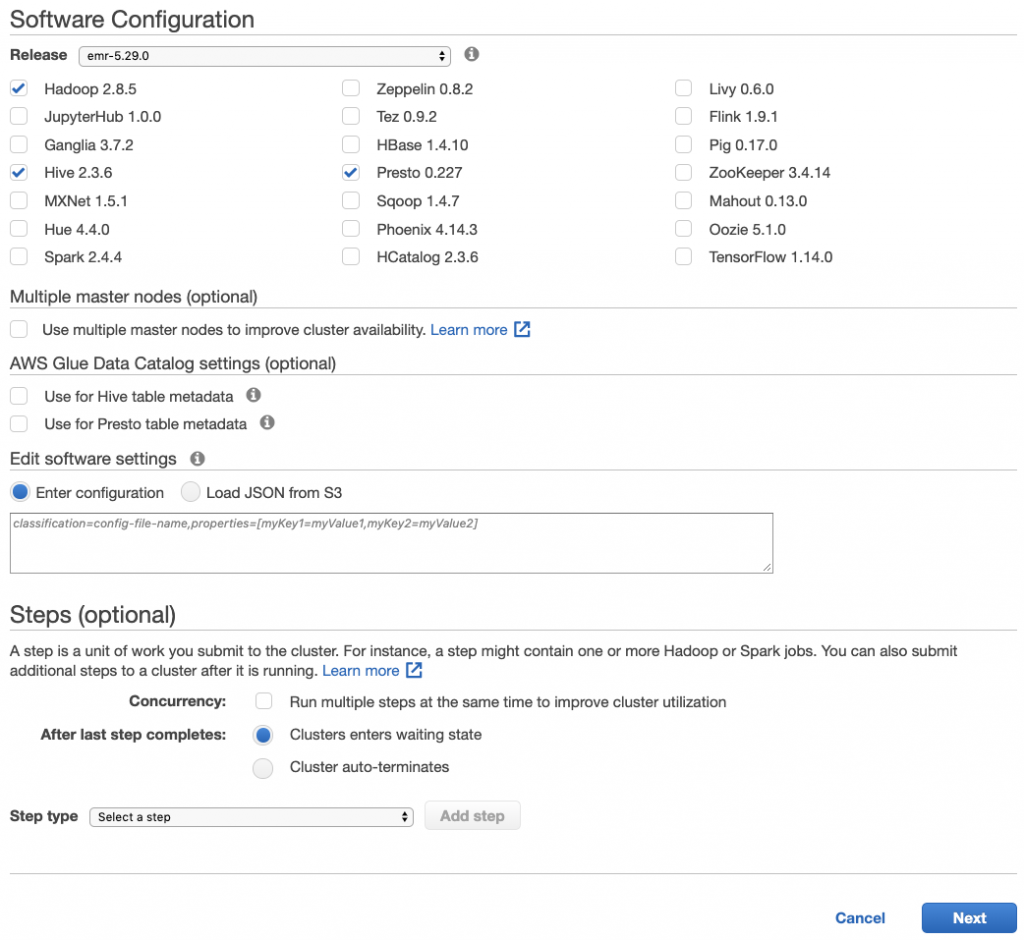
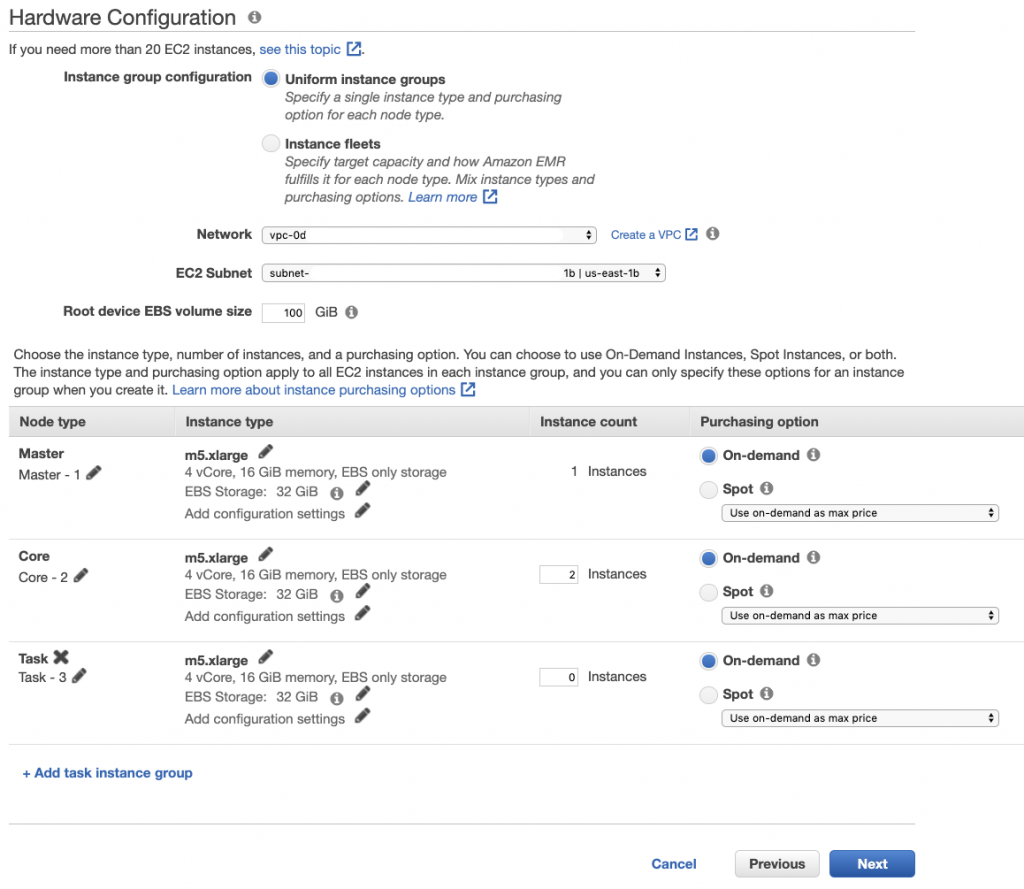
Make any change if needed for your VPC and Subnet settings.

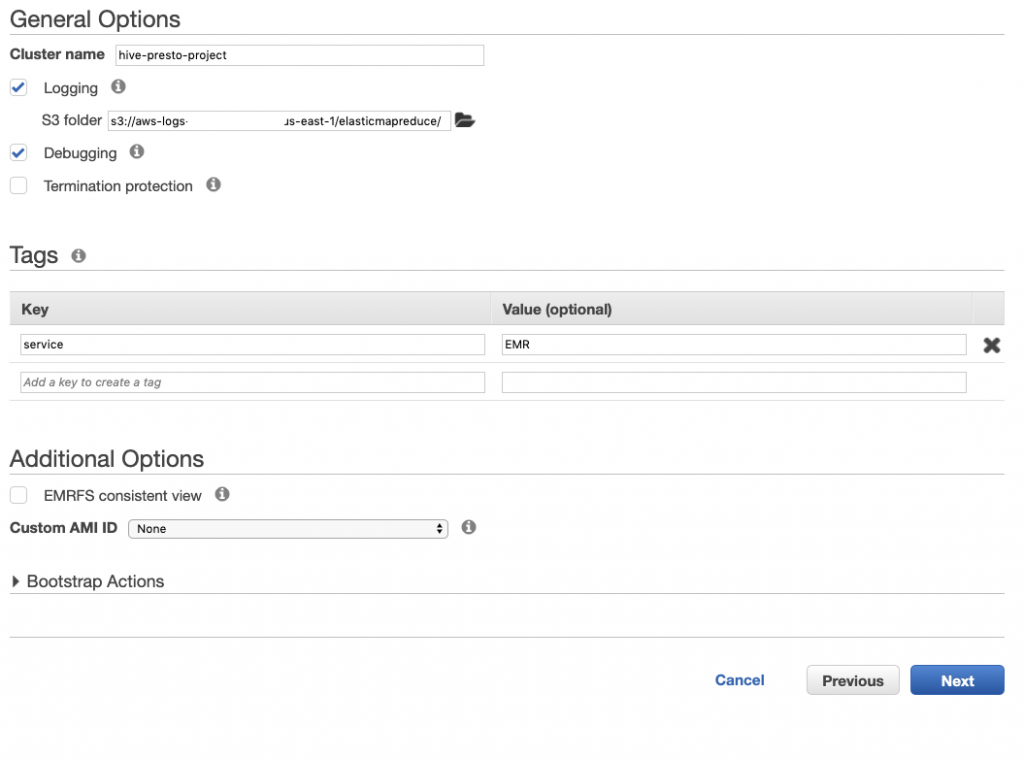
Next, choose a name for the cluster and setup the logging and optionally add some tag.
And lastly, choose the Key Pair or create one to be able to SSH into the instances.
It should take about 15 minutes before the cluster is ready to use.
I pushed the data in this git repo that you can download the data from the sample-data directory and add it to your S3 bucket. I used a simple script to load the data into S3 in the format that is suitable for partitioning Hive tables.
The S3-helper.py will read the data in the sample data directory and load them in S3. As you see the data is separated by the State in different files.
You can run the create_dir() method with your own bucket name and desire extension to create a structure like the following in your S3.
S3://<bucket-name>/elasticmapreduce/dbname/<CSV/Parquet>/state=<state>
Feel free to rename and change this structure, however, the last part which is state=<state> is important for Hive Partitioning. In Hive if we don’t partition our data, MapReduce has to go over all the dataset. This is slow and expensive since all data has to be read. Since we know our data is separated by state we can do partitioning and slice the data into different unique parts so MapReduce can only scan the relevant parts and improve the performance.
In Hive if we don’t partition our data, MapReduce has to go over all the dataset. Since we know our data is separated by state we can do partitioning and slice the data into different unique parts so MapReduce can only take a look at the relevant parts and improve the performance.
I used a simple Pyspark script to convert the CSV files to Parquet. I hope you can modify it in case you want to use that for your own data and convert your CSV files to Parquet format.
At this point, we should have our cluster up and running, the data should be loaded in S3 and now we can create the Hive tables.
First, lets SSH into your cluster. Make sure the security group that you are using allows inbound port 22 from your IP or 0.0.0.0/0. Also, make sure your EMR instance has access to your S3 bucket by either using an IAM role or an appropriate credential that you have in your ~/.aws/credentials.
Once you SSH into your cluster you can access hive and try to create a table for the CSV data like this.
create external table table-name (
gender string,
year int,
name string,
count int)
partitioned by (state string)
ROW FORMAT DELIMITED
fields terminated by ','
escaped by '\\'
lines terminated by '\n'
location 's3://bucket-name/[directory]/[directory]/';To create the table from Parquet format you can use the following
create external table table-name (
gender string,
year int,
name string,
count int)
partitioned by (state string)
STORED AS PARQUET
location 's3://bucket-name/[directory]/[directory]/';Before running your query run the following Hive command to add metadata about the partitions to the Hive catalogs.
msck repair table <table-name>;Now that we have our tables lets issue some simple SQL queries and see how is the performance differs if we use Hive Vs Presto. First, I will query the data to find the total number of babies born per year using the following query.
select year,sum(count) as total from namedb group by year order by total;I use both Presto and Hive for this query and get the same result. However, different performance.
Query the table from CSV data format.
| Hive | Presto | |
| Time Elapsed (Second) | 32.3 | 9 |
Next, I use the same query but this time on the second table that I created from the Parquet data format.
Query the table from Parquet data format.
| Hive | Presto | |
| Time Elapsed (Second) | 27.6 | 6 |
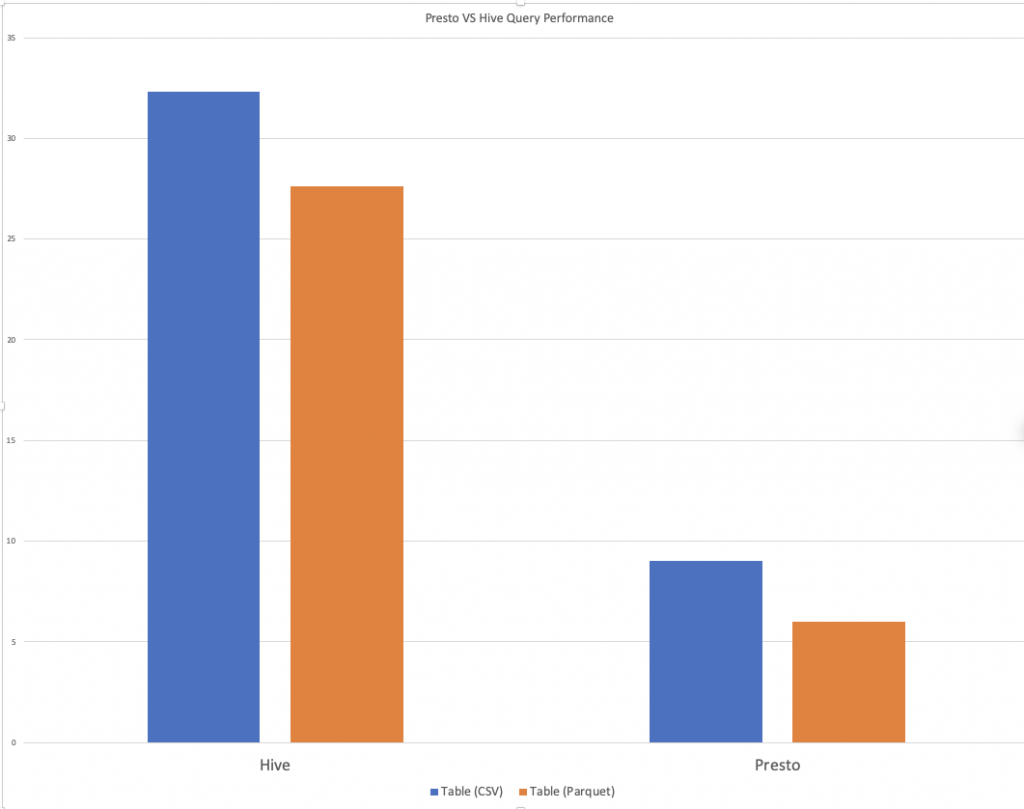
As you can see the performance differs significantly between Presto and Hive. The difference will be way more noticeable when the amount of data is huge and it goes to hundreds of gigabytes or even Petabytes.
The reason behind this performance improvement is that Presto uses in-memory parallel queries and significantly cuts down the disk IO. In contrast, Hive uses MapReduce which uses disk which adds significant IO delays.